
DAILY INSPECTION: M1255 CVV Strykers await daily checks and maintenance at Joint Base Lewis-McChord, Washington, in January 2024. This current maintenance prediction system only goes 30 days out. (Photo by Spc. Kourtney Nunnery, 5th Mobile Public Affairs Detachment)
Using machine learning to forecast maintenance readiness at the frontline unit level.
by Lt. Col. Nate Platz and Maj. Matt Gilbert
The Army’s current model to determine future equipment readiness levels falls short of enabling command decision-making in large-scale combat operations. The current model uses the bank time system, which calculates the sum of available equipment hours per fleet over a 30-day reporting window. But it does not consider external factors such as training conditions, personnel strength or parts availability, and only projects the current 30-day reporting period (from the 15th of the month to the 14th of the next month). With the availability of other analytical tools, the sustainment community should explore alternatives.
During a rotational deployment to Korea, leaders from 2nd Stryker Brigade Combat Team, 4th Infantry Division pursued an improved model to forecast equipment readiness using machine learning tools, while considering the influence of exogenous data. This research focused on forecasting equipment readiness for the Stryker fleet within one Stryker infantry battalion, specifically 1st Battalion, 41st Infantry Regiment (1-41). Training and maintenance data were included to establish impacts on current and future readiness. Machine learning then enabled the design of models based upon time-series data to assess their accuracy, with powerful results.
Using data available at the battalion level through U.S. Army systems of record, Soldiers from 2nd Stryker Brigade Combat Team developed a model to accurately predict one month of equipment readiness.

PRE-CHECK: Soldiers from 1-41 conduct pre-combat checks before loading up on the Strykers and crossing the line of departure during platoon certification in Korea. The current method of predicting maintenance doesn’t consider external factors such as training conditions, personnel strength or parts availability. (Photo by 1st Lt. Samuel Hughes, 1-41 Infantry Battalion Public Affairs)
THE APPROACH
The team gathered two years of daily maintenance and training data for one Stryker infantry battalion and analyzed the data using a linear regression. While the linear regression fell short of a sufficiently accurate predictive model, it helped identify statistically significant variables for determining maintenance readiness. With the regression analysis as a baseline, the team transitioned to more robust machine learning tools to find a best-fit predictive model. To assess accuracy, the team compared forecasted data with real data on a weekly basis over a 30-day period. To assess variation in forecasts and understand how each model learned, the team replaced forecasted data with current data on a weekly basis over the same 30-day period. At the conclusion of the study, each model’s 30-day forecasting performance was compared against the others to find which model provided the greatest accuracy over the longest period.
WHAT IS LINEAR REGRESSION? A linear regression is a statistical model that estimates the relationship between a dependent variable and independent variables. A dependent variable relies on independent variables to determine its value; in the study, the dependent variable was Stryker readiness. An independent variable is arbitrary and not reliant on outside values—essentially these were used to predict the dependent variable. Linear regression is used to determine if the dependent variable can be explained or predicted by the independent variables. |
In developing the model, the team tested three time-series forecasting tools using machine learning and catalogued their accuracy. Among the models used for predicting Stryker operational readiness rate, Prophet proved most accurate. Prophet is an open-source machine learning model developed by Meta Platforms designed for producing forecasts from time-series data. Other models tested that showed promise include random-search/random-forest and a Bayesian gradient booster regression, and all produced better results than legacy tools and methods. The random-search/random-forest is an ensemble machine learning model that creates nodes for testing and training data for evaluation; the gradient boosting regressor model is an ensemble machine learning model.
THE DATA AND METHODS OF COLLECTION
Initial attempts focused on data collection for an entire Stryker brigade but found too much variation in how training data was captured between battalions. To ensure data accuracy of training inputs, the team scaled down the sample to one Stryker infantry battalion. This allowed control for variations in training data when assessing the impact on Stryker maintenance readiness, which served as the dependent variable. The models used two datasets comprised of independent training and maintenance variables.
Training data was classified in a binary fashion to distinguish the days when equipment was operated from days when equipment sat idle. The data also included days when the battalion had no scheduled activity (a day of no scheduled activities, or DONSA) and days when the battalion was moving to and from training. This categorization method effectively weighted training volume for each day over time. The two datasets differed in the DONSA variable—one with this variable and one without.
Maintenance data was assembled from Global Combat Support System – Army, the U.S. Army’s system of record and a highly configured version of an enterprise resource planning system containing daily maintenance information. In our models, we considered overdue Stryker services, completed Stryker services, non-mission capable vehicles for maintenance and for supply and non-mission capable pacing vehicles for maintenance and for supply. The models then used observed values for all maintenance data inputs.
To create the forecast for each model, the research team entered the independent variables for the forecasted dates—this comprised the exogenous data (variables not affected by other variables in the system). Values for the exogenous data were obtained from the battalion training calendar for all training data and from the maintenance schedule for services and non-mission capable vehicles. Where appropriate, the team input the expected value for maintenance data and any planned training that fell within the category. This exogenous dataset was created for the next 60 days.

DATA CAPTURE: Stryker maintenance can be improved by exploiting untapped data that is readily available. (Photo by Maj. Matt Gilbert, 1-41 Infantry Battalion)
ANOMALIES AND OBSERVED INCONSISTENCIES
Completed services were observed to have an outsized impact on the forecast for gradient booster and random forest, as did DONSAs. A DONSA includes weekends and federal holidays. The periodicity of weekends within the DONSA variable resulted in inaccurate dips in predicted values, yielding inconsistencies. Removing the DONSA variable improved all models. The significance of the complete services variable suggests the importance of sticking to a service schedule at the unit level to accurately predict unit maintenance readiness. This also implies that senior leaders could make resourcing decisions from these models based on several compounding factors, such as when to schedule services and ensuring availability of service kits, as well as when to surge maintenance personnel to maintain equipment readiness.
APPLICATION
The Prophet model can aid commanders in understanding where maintenance will impact future operations and where future operations will impact readiness and operational endurance. Staffs can leverage this information for more precise assessments and improved planning. Picture the ability to understand the impact that changes to a training calendar have on Stryker readiness. For instance, when planned mechanic hours are diverted by unpredicted medical or other readiness requirements, a leader could communicate the tangible risk associated with those changes with precision. Using these models, commanders can test these unpredicted events to understand the impact on readiness.
A second application would be predicting Stryker readiness over a deployment period, such as a Korean Response Force rotation, a European Defender rotation or a combat training center rotation. Commanders would be able to identify periods where training will require a complimentary intense maintenance focus and plan accordingly or adjust their plan to meet Armywide training gate targets. Commanders also would be able to model the impact of changes in training plans or service schedules on equipment readiness during a rotation, informing decisions to maximize training and equipment readiness and identifying areas of risk.
A third application can be seen in an adaptation for large-scale combat operations. Instead of using a training calendar, a commander can use the operational synchronization matrix along with the maintenance plan to assemble the exogenous data and better understand which unit is best postured to be the main effort or when to commit a reserve for exploitation or reinforcement. This enables improved decision-making and informs recommendations from staff to commanders at echelon.
Battalions can replicate these models by exploiting untapped data that is readily available and generated as a byproduct of daily activities. The maintenance data used is common to all battalion maintenance technicians and the brigade support operations staff. The training data used is available and common to all battalion operations staff. Using a template and running the provided code into a Jupyter code environment—an online environment for writing and running programs, accessible on government computers through https://jupyter.org/—any battalion can produce these results.
These models were narrow in scope, and forecasted data was only observed for one month. Continued testing of these models will occur over a three-month period with 2nd Battalion, 23 Infantry Regiment, 1st Stryker Brigade Combat Team, 4th Infantry Division to determine how each model performs over a longer period with data structured at the outset. The team also will expand these models to the Stryker brigade and include all vehicle types to build a model capable of predicting maintenance readiness at the brigade level.
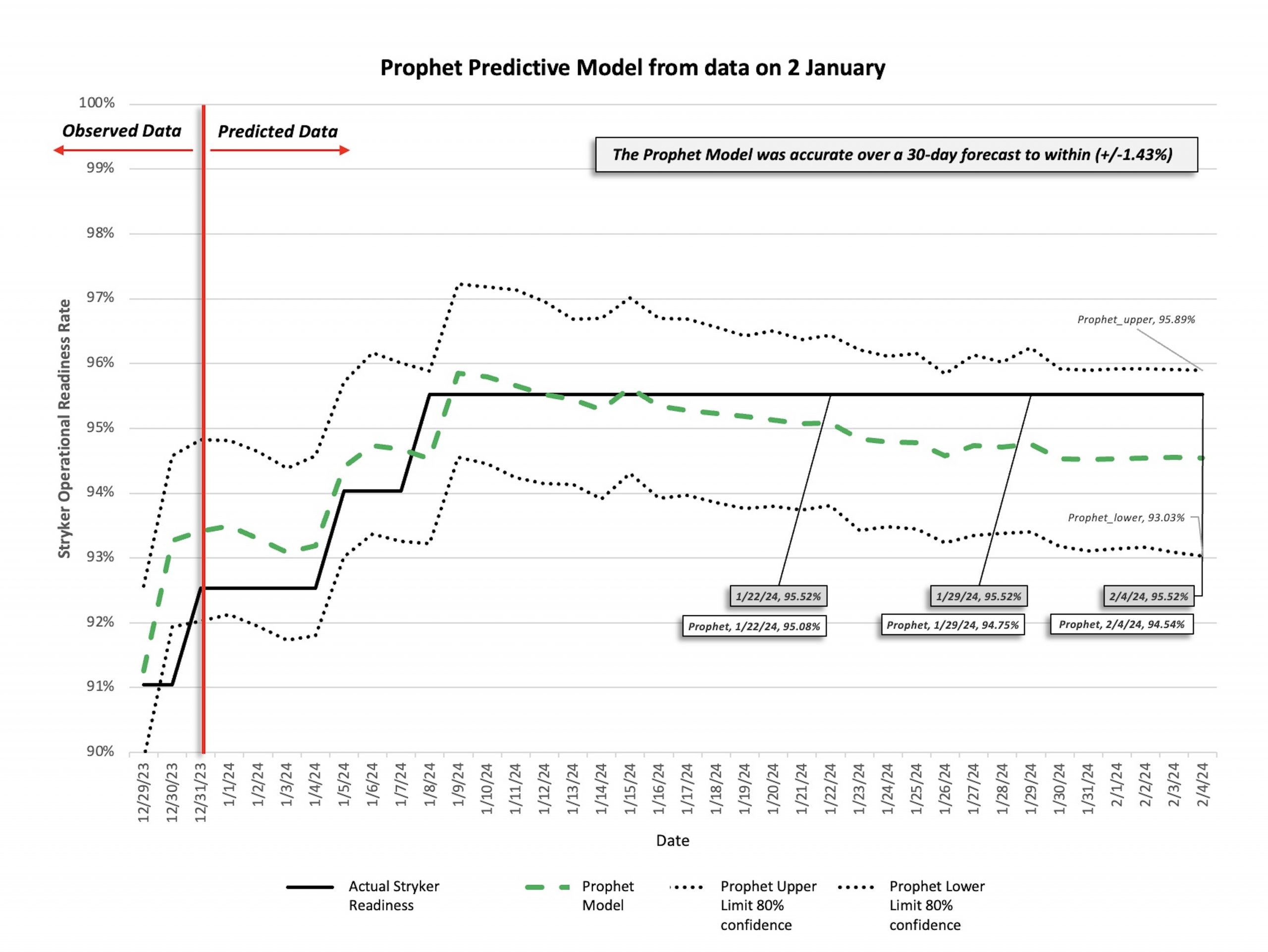
ON TRACK: A graph comparing the Prophet Model’s accuracy over a 30-day period with actual readiness. (Graphic by Capt. Bailey Smith, 704 Brigade Support Battalion)
RECOMMENDATIONS: WHERE THE ARMY NEEDS TO IMPROVE
Data: The foundation of every model is data. The success of these models is reliant on the research team exploiting untapped data, transforming that data to an interoperable format and then loading it into the models for training. This process revealed gaps in the availability of data at the tactical level and interoperability of that data throughout Army systems. Both gaps are areas that the Army has published strategic intent on improving through the Federal Data Strategy 2020 Action Plan and the Department of Defense Data, Analytics and Artificial Intelligence Adoption Strategy. For the Army to achieve the goals outlined in these strategic documents it must increase the availability of data and ensure the interoperability of that data once available.
Training: The Army must lower the cost of entry for data and analytics. Specifically, the Army needs to continue to teach data familiarity in its professional military education at all levels and expect a baseline competency across the force. Data literacy is becoming as essential as the current requirement of a basic ability to read and write. As data literacy increases, the force will become more comfortable interacting with and capturing data for informed decisions, improving the cognizance and utility of data collection and management. Additionally, leaders must improve their understanding of what data and models tell us. Looking at a chart predicting a future state is simple, but asking if the variables were statistically significant and understanding the adjusted significance of a model should be second nature to decision-makers for the Army to become a data-centric force. Education and training are the bridge between leaders and analysts, helping organizations better employ effectively.
Software: The Army cannot be datacentric without access to the tools to transform data and load it into models for analysis. Some of these tools are standard in the computers available for daily operations, but most are restricted by local or global network regulations. The Army needs to prioritize accessibility to such tools to enable future research on employing data for knowledge and understanding at echelon. Additionally, the Army should add data interoperability standards and practices that better align with machine learning requirements for all future software adoption contracts.
CONCLUSION
Rapid growth in the artificial intelligence (AI) has outpaced the Army’s and DOD’s current capability to modernize. We are fighting to keep pace through essential partnerships with Palantir, Amazon Web Services and Microsoft, all which provide systems that eventually may leverage AI tools against vast Army datasets—but we are still challenged in fully operationalizing AI at echelon. The models discussed are not a panacea for AI use and do not negate the Army’s need to rely on vital industry partnerships. They are an example of how units at echelon can integrate available tools for improved decision-making. These tools are available, or can be made available, for all units to employ by leveraging the talent of the Soldiers and without relying solely on commercial solutions. Coupling these tools with the solutions and technology already provided by industry partners is the key to ensuring that we successfully and maximally leverage AI for military purposes.
For more information, contact the authors at nathan.d.platz.mil@army.mil or matthew.d.gilbert4.mil@army.mil.
COL. NATE PLATZ is the battalion commander for 704th Brigade Support Battalion, 2nd Stryker Brigade Combat Team, 4th Infantry Division. He holds an MBA from William & Mary and a B.S. in computer science from Missouri State University.
MAJ. MATT GILBERT is the operations officer for 1-41 Infantry Battalion, 2nd Stryker Brigade Combat Team, 4th Infantry Division. He holds a Master of Security Studies with a concentration in artificial intelligence from Georgetown University and a B.S. in geopolitics from the United States Military Academy at West Point.